◆◆ よくある質問 (FAQ) ◆◆
非公式日本語翻訳(SFML2.5)
使い方がシンプルで、いろいろな OS で使える API です。ちなみに C++ で書かれてます。
同じようなものとして SDL というものがあるのですがご存知でしょうか? SDL の オブジェクト指向版、と考えてもらっても結構です。
SFML はいろいろな目的に役立つようにモジュールに分かれてます。
OpenGL を使うときの手軽なウィンドウ表示に使うこともできますし、
豊富なマルチメディア機能を利用してゲームなどを作ることもできます。
現在の最新版である SFML2.3 が完全に動作するのは Windows (8, 7, Vista, XP), Linux, macOS です。
32bit でも 64bit でも動きます。
古いバージョンの Windows でも動かしたい場合は、SFML2.0 を代わりに使うとよいです(参照 →
Windows 9x系 などが対象の削除機能について)。
SFML2.2 以降では実験的に iOS と Android がサポートされてます。
SFML は C++ で実装されてます。
そんなわけで、他の言語への
バインディングも用意されておりまして、
C, C#, C++/CLI, D, Ruby, Ocaml, Java, Python, VB.NET からも SFML を使うことができます。
SFML には依存しているライブラリがいくつかあります。なので、SFML を使ったアプリをビルドするには、依存しているライブラリも事前にインストールしておく必要があります。
Window および macOS では、必要なライブラリは全て SFML と一緒に入ってます。なので、別個に用意する必要もインストールする必要もありません。すぐにビルドできます。
Linux では残念ながら何も用意されてないので、あなたがマシンにインストールしているライブラリが頼みの綱です。
以下、必要なライブラリのリストです。
- pthread
- opengl
- xlib
- xrandr
- udev
- freetype
- jpeg
- openal
- flac
- vorbis
各パッケージの正確な名称はディストリビューションによって異なります。
あと、インストールするのは各パッケージの
development バージョンですので、忘れないでくださいね。
それから、SFML は内部的にもモジュール同士で依存し合っています。
Audio および Window は System モジュールに依存してます。Graphics は System と Window に依存してます。
たとえば Graphics モジュールを使うためには、Window モジュールと System モジュールもリンクする必要があります(GCC の場合はリンクする順番も重要)。
迷わず SFML2.4.2 を! なぜなら最新の機能とバグ修正がほどこされた安定版だからであります。
古いバージョン(1.6 など)はもうメンテナンスされてない上にバグも多くて、それに機能も貧弱です。
そんなわけで、最新版を使っておけば頭の痛い不具合に悩まされなくて済むってもんです。
※訳注:
2.5のリリース後でしたが、原文のFAQを確認した時点では「2.4.2」のままでした。
単に修正してないだけかな、とは思います(同じような箇所は他にも多数あり)。
SFML1.6 → 2.x系 への変更点を網羅したリストを見たい
完全に網羅はしてないのですが、
こちらのフォーラムのページをどうぞ。
上記のリストは 1.6 → 2.0 の間に行われた全ての変更が載っているわけではないです。
なにしろ一年以上前に書かれたリストでして、その後、下記のような大きな更新もありました。
- グラフィック関連の API が書き直された
- sf::Time API が追加
- デフォルトでビルトインされていた Arial フォントが削除された
- getWidth() および getHeight() がなくなって、代わりに getSize() に置き換えられた
- 命名規則が変更された(詳しくはこちら)
ノーであります。
SFML の開発チームは決心しているのです。SFML はあくまでも 2D グラフィックを簡単に扱えるライブラリとして開発していこう、と……。
そんなわけで、単刀直入に言うと、現在も今後も、SFML で 3D がサポートされることはないです。
なのですが、Irrlicht などの 3Dライブラリを使いつつ、SFML をウィンドウ表示用の補助ライブラリとして使うことはできます。
または、生の OpenGL を 3D用に使いつつ、2D のレンダリングエンジンとして SFML を使うこともできます。問題なしです。
ただし、このお話がオススメできるのは、3D の最小限の機能を使うときだけです。
3D の機能をグラフィックパイプラインだけを通して使いこなすのはとっても大変です。
役に立ちたい人のためのガイドラインを見てね!
SFML は プログラミングの勉強に役立つ?(C++)
一般論として言えば、どんな方法でもプログラミングの勉強はできます。
問題はこうです。
どんな方法が最も効果的な勉強方法なのか?
結論だけ言ってしまうと、C++ の基本的な機能を把握しようと思っているなら SFML を取っ掛かりにするのはよろしくありません。
SFML では C++ の基本的な機能だけでなく、上級者向けの機能も使われてます。
最初のうちはそれなりに勉強になることもあるかもしれませんが、勉強した内容を役立てていけるかどうかは別問題です。
おそらく、C++ に元々ある標準ライブラリだけに集中した方が、より深く、早く、学習が進むはずです。
そうした方が、SFML の API に惑わされずに C++ という言語の仕様を学習できるでしょう。
グラフィック面では地味になってしまいますが 世の中には stdin や stdout だけを使ったテキストベースのゲームの良質なサンプルがたくさんあります。
どんな情報源でプログラミング(C++)を勉強するのかも、完全にあなた次第です。
ただ、ネット上にあるサンプルやチュートリアルは鵜呑みにしない方がよいです。
書いた人の悪い癖が出ている可能性があります。しかし初心者には判断しにくい。
一番安全なのは、言語の開発に現在進行形で関わっているような有名な著者の書いた参考書を見ながら勉強することです(この
リストを参照)。
そういう本や著者なら間違いなく言語の大事なポイントを把握しているし、そこから効果的にプログラミングを学ぶことができます。
多くの初心者にとっては意外かもしれませんが、C++ は今でも発展途上です。C++11 や C++14 の標準化が行われた後でも更新が続いています。
なので古い本やネット上の古い情報をもとに勉強すると、言語の全体像を知ることができなかったり、非推奨の古い手法を身に着けてしまうかもしれません。
基本を把握した後は自分で積極的に新機能について情報収集するようにしましょう!
以下に、自分が SFML を使えるレベルに到達しているかどうかのチェックリストを用意しました。
SFML を使うにあたって、是非とも知っておくべきプログラミングの知識です。
・基本的なこと。SFML でプログラミングをするために必要なこと:
- コンパイル、ビルド
- 基本的なプログラムの仕組み(main()関数、ヘッダー、インクルード、などなど)
- 基本的な変数の型
- 構造体
- 制御構文 (if, for, while ...)
- 関数の基本、呼び出し情報(シグネチャ)
- 関数でのパラメータの受け渡し
- クラスおよび基本的なオブジェクト指向
- STL
- 動的メモリ確保、ポインタ
- 型キャスト
- オブジェクト指向上級編(継承、ポリモーフィズム)
- プログラムの仕組み上級編(ヘッダーファイル、リンク)
- デバッグ技術 イザというときのための重要事項!
・上級編。必須ではないけれど、知っておくといいこと:
- テンプレート
- 演算子のオーバーロード
- 名前空間
- ムーブセマンティクスおよび C++11 の他の機能
- メタプログラミング
・メンテナンスや生産性に関するスキル、これも必須ではないけれど知っていると素敵:
- プロファイラ
- 最適化
- コーディング規約
- リファクタリング
- コードの組織化:抽象化、モジュール化、責任の分散
- イディオム: RAII, Pimpl, Erase-Remove, Copy & Swap
- Advanced data structures and algorithms
- ライブラリの書き方、APIデザイン
- クロスプラットフォームなビルドツール
- ソフトウェア構成管理(SCM)、Git, SVN, Hg など
・より深い理解、背後で何が起きているのかを把握するための知識:
- グラフィックスパイプライン (OpenGL)
- ネットワーク (TCP, UDP)
- オーディオの知識(サンプリングレート、減衰、波動特性)
- OS の知識(1つの OS だけじゃなく)
- ハードウェアの知識(CPU、命令パイプライン、RAM、キャッシュ、ページング)
まずは、チュートリアルやドキュメントをよく読もう。それから、同じ質問がすでにされてないかをチェック。
それでもまだ
SFML に関する疑問があれば、
フォーラムへ。
覚えておいて欲しいのですが、SFML を使うのは C++ プログラミングの学習方法としてはあまりいい方法ではありません。
なので、C++ の全般的なことについての質問は、C++ を専門としている人たちのいるもっといいフォーラムで訊ねるとよいでしょう。
ちなみに、SFML公式の
IRC チャットもあるよ。
各バージョンの SFML のチュートリアルが
ここにあります。
チュートリアルの最初のパートは環境設定の方法についてです。
その中に、CMake を使ってあなたのお好きなビルドツールで SFML をビルドする方法や、IDEのセッティング方法が書いてあります
(あなたの使ってる IDE が含まれてますように)。
非公式ですが、フォーラムにスレッドがあり、特定のプラットフォームのリリース前の最新版が公開されています。
スレッドへのリンク
おいらの開発環境で SFML を使う方法を教えて!
有名どころの IDE での設定方法はチュートリアルのページで手取り足取り解説しております。
チュートリアルの
「開発環境を整えよう」をチェックせよ!
ファイルがたくさんあるんですけど、どれ を どう リンク すればいい?
SFML を使うには、必要な機能のライブラリファイルをアナタの開発中のアプリケーションにリンクしてあげる必要があります。
SFML は5つのモジュールに分かれてます:
- システム:sfml-system
- ウィンドウ:sfml-window
- グラフィックス:sfml-graphics
- オーディオ:sfml-audio
- ネットワーク:sfml-network
モジュールはお互いに依存し合ってます。
たとえば、グラフィックスモジュールを使うには、ウィンドウモジュールとシステムモジュールもリンクしないといけません。
依存性一覧:
- システム:他のモジュールへの依存なし。単独で使えます。
- ウィンドウ:システムモジュールに依存
- グラフィックス:ウィンドウとシステムモジュールに依存
- オーディオ:システムモジュールに依存
- ネットワーク:システムモジュールに依存
上記の通り、システムモジュールは必ずリンクしてあげることになります。
リンカーによっては、リンクする順番の指定を気にする必要があります。
GCC(MinGW も同じく)では、依存されるライブラリ(他のライブラリが依存しているライブラリ)は依存するライブラリ(別のライブラリに依存するライブラリ)の後に指定される必要があります。
全てのモジュールをリンクする GCC のコマンドラインのサンプル:
g++ main.o -o sfml-app -lsfml-graphics -lsfml-window -lsfml-audio -lsfml-network -lsfml-system
この件については
こちらのフォーラムの投稿でも解説されてます。
Code::Blocks では、リンクするライブラリのリストの中で、被依存ライブラリを依存するライブラリの後に指定する必要があります。
スタティックリンク用の SFML ライブラリをリンクしましょう。
ファイル名の後ろに "-s" がついているのがスタティックリンク用です。たとえば sfml-graphics-s など。
次に、プリプロセッサとして "SFML_STATIC" を追加しましょう。
そして、いつものように、デバッグ用のライブラリ(語尾が "-d")をデバッグモードにて、リリース用のライブラリ(語尾に "-d" なし)をリリースモードにてリンクするように設定です。
さて、以前のバージョンでは Windows の場合、全ての依存ライブラリが SFML に含まれてました。
ところが、この仕様は変更になりました。いろいろあった問題を一網打尽にしつつ、他のプラットフォームでの使い方と統一するためです(
こんな議論がありました)。
そんなわけで現在の SFML は Linux でも Windows でも同じような振る舞いをします。
ということは……Windows 上でも SFML が依存しているライブラリを自分でリンクしてあげないといけない、ということだったりします(スタティックリンクの場合 )。
と、言われても、何をリンクすればいいのか、わかんないですよね。
一覧を載せておきます:
Windows
- sfml-window
- sfml-system
- opengl32
- winmm
- gdi32
- sfml-graphics
- sfml-system
- sfml-window
- opengl32
- freetype
- jpeg
- sfml-audio
- sfml-system
- openal32
- flac
- vorbisenc
- vorbisfile
- vorbis
- ogg
- sfml-network
- sfml-system
Note:Windows の全依存ファイルは
extlibs フォルダに入ってます。
※ 訳注 ※
これは SFML2.4 の情報です。バージョンによってリンクすべきライブラリが異なっています。
お使いの SFML のバージョンを確認してください。
スタティックリンクの模式図です。
sfml-window-s sfml-system-s opengl32 winmm gdi32
| | | | |
| +-------+ | | |
| | +------------------+ | |
| | | +------------------------+ |
| | | | +-----------------------------+
| | | | |
v v v v v
example.exe
次のファイルフォーマットがサポートされてます:
bmp, dds, jpg, png, tga, psd
ただし、各フォーマットの全ての派生フォーマットがサポートされてるわけではないです。
公式ドキュメントも参照のこと。
テクスチャが表示されない! 真っ白になる! 真っ黒になる!
さては sf::Texture オブジェクトを破棄してしまってますね?
sf::Sprite は sf::Texture オブジェクトへの参照を保持してるだけなのです。
なので、sf::Sprite に使われる可能性のあるうちは sf::Texture を生きてる状態にしておかないといけません。
というか、テクスチャをスプライトに紐付けるのを忘れてる、なんてことはないですか?
スプライトクラスの setTexture() 関数を使って、使いたいテクスチャ(のメモリ)を設定してください。
テクスチャオブジェクトが別のメモリへ移動したときも、setTexture() 関数で新たなメモリをスプライトに教えてあげる必要があります。
というか、テクスチャのメモリが移動しないように、上手にオブジェクトを管理できると、もっといいですね。
sf::Image と sf::Texture の違いは何?
ぶっちゃけ同じです。
問題は "どう違うか?" というよりも "データがどこに格納されているか?" です。
sf::Image の場合、画像データは クライアント側のメモリに格納されています。つまり、システムRAMの中 です。
その中では、データはあくまでも バイト列です( 1ピクセルごとに 4バイト)。このデータが、画面で見ることができる画像を構成してます。
sf::Texture も同じような画像データなのですが、サーバ側のメモリに格納されています。つまり、GPU の隣にある VRAM です。
このメモリは OpenGL が管理してます。sf::Texture は単に VRAM 内の該当するメモリブロックへのハンドラに過ぎません。
世間にはテクスチャのメモリ構造はいろいろありますが、SFML では sf::Image と同じ形式のもの(4バイトRGBA)を sf::Texture にも使ってます。
原因はいろいろあり得ます。ソースコードと動作環境次第です。
が、まずは draw 関数の呼び出し回数を疑ってみてください。
大量の sf::Sprite を使うということは、それと同じ分、大量に draw 関数をコールするということになります。
draw関数をコールするたびに、内部で毎回、レンダリングターゲットが変更されます。
変更は一回だけにしておいた方が効率的かもしれないのですが、SFML ではそういう仕様になってます。
なぜかというと、その「効率的かもしれない仕様」にすると、sf::Sprite で出来ることが制限されてしまうからです。
GPU の制限のために単一のテクスチャを嫌でも使うようにしないといけなくなったりもするのです。
大量にスプライトを使っている状況で FPS を上げるには、自前で生の sf::Vertex や sf::VertexArray を使うか、または同じ原理のことをするしかありません。
とは言え自前でそういうことをしたからと言って魔法のように FPS が急上昇するとは限りません。
大人しくラッパーを使っておいた方がコードをキレイに保ちつつ、思い通りのレンダリングができると思います。
SFML Wiki Souce Codes に
タイルマップ表示や、複数のスプライトで同じテクスチャを使い回したりするための高速なレンダリングのクラスがあります。
VSync(垂直同期) と window.setFramerateLimit のどちらがいい? 他の方法もある?
目的によります。
大まかに言えばどちらも垂直同期とフレームレートの制御を行うことができて、同じ結果になります。
が、悪魔は細部に宿っているのです。
昔々……あるところにブラウン管(CRT)というものがありました。この中では、電子ビームが磁力で制御されて縦横に発射されるようになってます。
この電子ビームは「ペン」みたいなものです。この「ペン」で毎フレーム、全ピクセルが描画されます。
電子ビームが毎フレーム動き回るわけですから、これは時間のかかる処理です。このことが、ディスプレイがサポートするリフレッシュレートの最大値を決める要因になっています。
電子ビームが一本だと、画面には一色しか表示できません。
フルカラーの表示をするには各色要素に対応して3本のビームが必要です。
そして、それらのビームはグラフィックカードから送られる画面表示のデータでコントロールされる、というわけです。
理想的な想定としては、毎フレーム、電子ビームが発射される直前に、新たな画面表示用データのセットがモニターに送信されることです。
つまり、GPU がモニターと同期されている、ということです。電子ビームが発射開始の位置につくまで、フレームバッファの更新を待機させている。
もし電子ビームが発射されている最中にフレームバッファが更新されてしまうと、画面の半分だけ古いデータが表示され、半分だけ新しいデータが表示されることになります。
これが
ティアリングです。これを防ぐことが垂直同期の目的であり、現在もこの機能が存続している理由です。
将来的には、この問題は徐々になくなっていくでしょう。
そしていつかは、垂直同期は不要になり、ハードウェアでのサポートは削除されることでしょう。
VSync は通常、ドライバ内のバッファスワップに対するブロッキングコールとして実装されています。
これが VSync が現存している理由であり、フレームレートの制御の代用品として誤用される理由です。
ドライバは同期をとりたくてもフレームを破棄する権限を持ってません。
なので、もしアプリケーションがフレームを生成する処理が高速すぎると、VSync のブロッキングコールで、その処理速度が抑えられる必要があります。
もしアプリケーションがフレームを生成する処理速度が不足していると、
ドライバはフレームを重複させるしかなくなります。すると、おかしな結果になってしまう。
多くの実装では、ドライバはウェイトループでバッファスワップをブロックしています。そうして、ハードウェアの性能が制限している最適なタイミングに合わせようとします。
CPU への負荷を抑えるために VSync を使うと非生産的になりかねないのは、まさにこの理由によります。
そうした使い方が誤用だということを理解すると、VSync の必要性が見えてきます。
VSync はハードウェアの制限による問題を解決するためのものです。
それをアプリケーションの内部的な処理をコントロールすることや CPU への負荷を制御するために使うのは率直に言って誤用です。
そういう目的のためには、CPU フレームレートを制御する機能を使いましょう。
他のスレッドやプロセスへ CPUのタイムスライスを明け渡したり、処理が何もないときには CPU をスリープさせたりする機能です。
もう一つ注意点があります。異なるシステムには異なるハードウェアがあり、リフレッシュレートが異なっている可能性があります。
こうした環境で フレームレートを制御するために VSync を使っていると、意図しない フレームレートになってしまいます。
もし、シミュレーションのような処理を異なるシステムでも同じように動作させることが目的ならば、やはり VSync を使ってはいけません。
VSync を使っていいのは、ティアリングの問題が発生し得ることがわかっていてそれを防ぐためだけです。そのほかの目的にはフレームレート制御で対応しましょう。
すごーくマニアックなケースでは垂直同期とフレームレート制御を両方使うこともあるのですが、それはこの FAQ の範囲を超えてしまいます。
1つのスプライトを使い回すのと、テクスチャごとにスプライトを作るのと どっちがいい?
一般論としては、描画するオブジェクトが少ないほど、アプリケーションの処理速度は速くなります。
逆に、描画するオブジェクトが多ければ、その分、処理に時間がかかってしまいます。大体そういう法則があります。
が、もし可能であれば、毎回同時に描画されるオブジェクトをグループ化して、1つのスプライトで描画されるようにしてみましょう。
そうすると、処理速度を節約することができます。
やっちゃいけないのは単一の sf::Sprite に対して、描画するたびに別々の sf::Texture を設定しなおすことです。
単一の sf::Sprite を使ってはいるのですが、結局、描画のたびに draw 関数がコールされることになります。
また、1フレームの間に sf::Texture を sf::Sprite に設定する処理を何度も繰り返していると、パフォーマンスが著しく低下してしまいます。
簡易的なカリングを試してみるのもよいでしょう。
カリングとは、他のオブジェクトに隠れて画面に出てこないことが確定しているオブジェクトの描画を行わない、ということです。
これができると不要な drawコールをしなくて済むので、パフォーマンスが向上します。
LocalBounds と GlobalBounds の違いは何?
まずは、ローカルとグローバルの座標系についてお勉強しましょう。
話をわかりやすくするために、森の中を歩いている場面を想像してください。
そこへお友達がやってきて、あなたに質問しました。
「何をしているの?」
あなたは答えます。
「森の中を歩いているのだよ」
そしてあなたとお友達はお話しながら一緒に歩くことにしました。
さて、次にどんな質問が飛んでくるかは明白ですね。
「あなたは今どこにいるの? どこへ向かっているの?」
あなたが、
「今、川沿いにいる。そして上流に向かっているのだよ」
と答えました。
ですが、お友達はこう返します。
「それじゃ、どこのことなのかわからないよ」
というのも、この森はとっても広くて、川がいくつもあるからです。なるほど。
あなたはお友達に GPS の現在位置を教えて、向かっている方角はコンパスで教えることにしました。
最初にあなたがお友達に教えようとしたのは、森の中のあなたがいる近辺のローカル座標系での位置です。
森のその近辺では川は1つしかありませんでした。
なので、同じ近辺にいる人には「川沿いを上流に向かっている」と言うだけで充分でした。
しかし、あなたが森の外にいる場合はグローバル座標系を使うしかありません。
この場合、 WGS (GPS) の座標系での位置と、向かっている方向、です。
SFML では、描画対象となるオブジェクトの座標系はこれと同じ原則に従います。
バウンズ(境界線)はローカル座標系にもグローバル座標系にも帰することができます。
通常、グローバル座標系はそのオブジェクトを描画するレンダリングターゲットの座標系です。
あるオブジェクトのローカルバウンズとは、そのオブジェクトの座標系で (0, 0) に位置する四角形です。
その四角形はそのオブジェクトをすっぽりと包み込むだけの幅と高さを持っています。
SFML では バウンズ(境界線)は常に AABB(軸に平行な四角形)です。
オブジェクトを回転させた後であっても、です。
あるオブジェクトのグローバルバウンズとは、そのオブジェクトのローカルバウンズに、そのオブジェクトのトランスフォーム情報(位置・倍率・回転)を適用したものと同じです。
オブジェクト自身がグローバル座標系で (0, 0) 以外に位置している場合、オフセット値はグローバルバウンズの四角形の座標値と同一になります。
さて、わかりにくいのは回転した場合です。
回転されたグローバルバウンズの幅や高さは、どのように計算されるのでしょうか?
ローカルバウンズの四角形を4つの点として思い浮かべてみましょう。
それら4つの点に、そのオブジェクトのトランスフォーム情報(位置・倍率・回転)が適用されて回転が行われます。
そして、回転後の各点の位置を含むような AABB が作成されます。
オブジェクトの回転度数が直角の倍数ではない場合は、さっき説明した原理に従います。
オブジェクトのグローバルバウンズは、ほぼ必ず、ローカルバウンズよりも大きくなります。
イメージが思い浮かびにくい場合は、紙に四角形を描いてみてください。
紙を回転させて、四角形を囲むように AABB を描いてみましょう。
まず最初に確認。FPS値は特定の値の付近をうろうろしてませんか?(60, 75, 80, 144, etc...)
もし、そうなら、どこかで人為的に FPS が制限されている可能性大です。
次のステップに進む前に、そういう人為的な制御がどこにもないことを よーく、よーーく確認してください。
さて、アプリケーションを開発していて FPS の低さに悩んでいる人は、FPS の低さはグラフィックスのせいだと思いがちです。
もちろんグラフィックスが原因の場合もありますが、そうとは限らないのです。
大抵、アプリケーション側では グラフィックス関連の処理よりも CPU関連の処理がたくさん行われています。
このとき、このアプリケーションは "CPUバウンド" である、と言います。逆の場合は "GPUバウンド" です。
おおまかな方法ですが、あなたのアプリケーションが CPUバウンドかどうかを調べるには、アプリケーションの CPU使用率をモニタリングするとよいです。
もし、使用率がほぼ 100% ならば、CPUバウンドである可能性が高いと言えます。
その場合、フレーム毎の CPU ロードを減らせばフレーム毎の処理時間を短くすることができます。つまり、FPS が向上します。
自分のアプリケーションが CPUバウンドかな? と思ったら、ホットスポットを探しましょう。
ホットスポットというのは CPU が最も処理に時間がかかっている箇所のことです。
ホットスポットを探すにはパフォーマンスプロファイラを使います。
ちゃんとしたプロファイラであれば、ホットスポットを見つける役に立つはずです。
見つかったらそこを中心にコードを見直して最適化を試みましょう。観点は CPU関連の処理を見直すことです(GPU関連の処理ではなく)。
自分のアプリケーションが CPUバウンドではなさそうだけど、やっぱり FPS が低い。そのときは、描画周りの処理をどんなふうに書いているのかを見直してみましょう。
SFML はレンダリングに OpenGL を使っています。
OpenGL を使った描画処理にかかる時間のうち、ドライバ や グラフィックカードとの通信に使われているのは少しだけです。
通常なら、ドライバ が行う処理が少ないほど、またグラフィックカードとの通信が少ないほど、グラフィックスの処理のパフォーマンスは良くなります。
したがって、最適化として最初に行うのは、一度により多くのオブジェクトが描画されるように、小さなオブジェクトをグループ化して大きなオブジェクトにまとめることです。
SFML 自身がそれを自動で行ってくれるわけではありません。自分でコーディングを工夫する必要があります。
より効率的に描画するにはどういうフローにすればいいのかを考えて、それを SFML の機能を使ってコーディングしてください。
描画処理の最適化の基本セオリーは
"draw() 関数の呼び出しが少ないほど、1フレームの処理時間が短縮される" です。
そのほかの最適化の手法についてはフォーラムの記事を探すか、スレッドを作成してください。
その際はそれまでに自分がやってきたことの詳細情報を書き添えるのを忘れないでくださいね。
RenderTextures が私のマシンでは動作しないよ!
sfml-graphics に関連することは後回しにして、まずは次のことを確認してください。
ドライバはインストールされてますか? SFML がハードウェアにアクセスするために必要です。
プレインストールされているドライバがあったとしても、そのドライバにバグがないとも限りません。ハードウェアの性能をちゃんと引き出せているとも限りません。
新しいドライバがリリースされていないかどうか確認して、アップデートしましょう。
特にデスクトップマシンの場合はドライバを見直すことで不具合が解消することがあります。
ドライバが最新であることを確認したら、次はグラフィックカードが OpenGL のフレームバッファオブジェクト(GL_EXT_framebuffer_object のエクステンション)
をサポートしているかどうかを確認してみてください。
サポートされているにも関わらず RenderTextures が動作しないならば、フォーラムで質問してください。
その際はそれまでにしてきたことや集めた情報についての詳細を書き添えるのを忘れずに。すぐに誰かが回答してくれるでしょう。
グラフィックカードが OpenGL のフレームバッファオブジェクトをサポートしていなくても大丈夫です。
SFML には余っているコンテキストのフレームバッファを使ってレンダリングをする機能があるのです。
パフォーマンスはネイティブ処理より "[ほんの少し遅い]~[メチャクチャ遅い]" の間です。何しろソフトウェアレンダリングですから。
2つ目の方法でもうまくいかず、ハードウェアの性能にも問題ないならば、それまでやってきたことや集めた情報を書き添えてフォーラムで質問してください。
アニメーションや動きが滑らかじゃない! カクカクする!
よくあるのは、アプリケーションのフレームレートが安定していることをアテにし過ぎているというケースです。
フレームレートを特定の値に固定しておくには多大な努力と OS 内部の処理の仕組みに関する知識が必要です。
詳しくは
ここ や
ここ を読んでください。
ちなみに垂直同期を使うのは問題外ですよ? それをやると実行環境によって異なるフレームレートになってしまいます。
さて、次のようなシンプルなループを書いたとします:
while( window.isOpen() ) {
/*
イベント処理
*/
// スプライトの位置を更新
sprite.move( 1.f, 0.f );
// 描画
window.clear();
window.draw( sprite );
window.display();
}
このループではスプライトを 毎フレーム "1" ずつ、X軸に沿ってプラスの方向へ動かしています。
単位はラスタ画像のものです。ピクセルなど。
このループ処理の問題点は 1フレームの間にスプライトの位置を変化させる量が固定されていることです。
これだと、多くのフレームが経過すれば、スプライトの移動距離も長くなります。
いつも同じペースでフレームが処理されるならスプライトは同じ速度で動き続けるでしょう。
しかし、上で述べたことを思い出してください。なかなかそういう理想的なことは実現してくれません。
フレームレートは常に揺れ動いているものです。なので、スプライトのフレーム毎の移動量を固定してしまうと、
スプライトの見た目の移動速度はアプリケーションの実行環境によって違ってしまうことになります。
フレームの処理速度が速いほど、一定の時間内に処理し終わるフレームの数が多いということです。
つまり、スプライトの移動距離も長くなる。したがって、見た目のスピードが速くなる。
この問題を解決策は、スプライトの移動量をフレームレートから切り離すことです。
これを実装するために、速度というものについて考えてみましょう。
速度は通常、m/s や km/h などで表されます。これはつまり、移動した距離を、経過した時間で割った値です。
速度を "フレーム毎の移動ピクセル数" として実装するのは問題あり、なのでした。
ピクセルは距離と見なすことができますが、フレーム数を時間の単位と見なすことはできません。
ではスプライトの速度をどういうふうに実装するといいでしょうか?
たとえば 1秒ごとに 100pixel ということにしてみましょう。
では次にそれを、毎フレームの移動量に変換しましょう。
速度とは何だったでしょうか? 移動距離を経過時間で割った値、でしたね。
ということは、単純計算で、任意の秒では何pixel なのかを "1秒につき100pixel" をもとに求めることができます。
移動距離 = 速度 × 経過時間
あくまで単純計算ですが大体そう考えて間違いありません。
さて、速度は上記のように定義できるとして、経過時間はどうやって求めればいいでしょうか?
SFML の sf::Clock を使えば一発で解決です。
sf::Clock の使い方については
チュートリアルやドキュメントを見てくださいませ。
毎フレームの処理の中でまず最初に、前回のフレームが処理されてからどれだけの時間が経過したのかを求めることです。
こういう求め方だと厳密な値にはならないのですが、今回の目的を達成するにはそれで充分です。
さて、こうして求めた経過時間をもとに、単純な計算で、そのフレームでのスプライトをどれだけ移動させればいいのかを求めることができます。
たとえばこういう感じ:
// 速度(1秒ごとの移動ピクセル数)
float speed = 100.f;
// 時間計測用のオブジェクト
sf::Clock clock;
while( window.isOpen() ) {
/*
イベント処理
*/
// 経過時間を取得
float delta = clock.restart().asSeconds();
// スプライトの位置を更新
sprite.move( speed * delta, 0.f );
// 描画
window.clear();
window.draw( sprite );
window.display();
}
このコードなら、フレームレートに関係なく、スプライトを 1秒ごとに 100pixel 動かします。
1つ注意点があります。コードの中で使う物的な単位は統一しておくようにしましょう。
たとえば速度の仕様として "秒ごとの pixel数" を使ったなら、経過時間の単位としても "秒" を使う、ということです。
そこを一致させておかないと期待通りの結果になりません。
ここでは FAQ ということでシンプルな方法を紹介しましたが、他にもこの問題の解決策はいろいろとあります。
SFML で使えるオーディオデータのフォーマットは?
Wav と Ogg/vorbis と Flac です。
残念ながら MP3 は Thompson Multimedia のライセンス下にあるので SFML のサポートには含まれてません。
MP3 のライセンスについての詳しい話は
http://www.mp3licensing.com に載ってます。
アプリがちゃんとビルドできて動作もしているにも関わらずスピーカーから音が出てこないとしたら、初歩的なことを確認してみましょう。
SFML の動作を疑う前に、スピーカーやプラグインがちゃんと動作しているかどうかを確認です。
お手持ちの音声ファイルを Window Media Player や
VLC などの他のメディアプレイヤーで再生してみてください。
もし再生に失敗するならは、PC の音声がミュートになっていないかを確認です。スピーカーのボリュームが小さすぎないかも確認。
他のメディアプレイヤーでは音声が再生できるのに SFML では音が出ないとしたら、問題は SFML の側にある、ということです。
まずはその○○○の背後で動いているネットワーク処理の仕組みを理解しましょう。
見た目がどんなに複雑なアプリケーションでも、データを送受信する仕組みや、送受信されているデータの種類についてはシンプルな仕組みがあります。
主に2種類の仕組みがあります。
- クライアント・サーバ型
- クライアント・クライアント型(P2P)
一般的に、クライアント・サーバ型の方が設定が簡単で、クライアント・クライアント型よりも高いパフォーマンスを得られます。
なぜかというと、複数のトラフィックを処理するための専用のサーバを用意しているからです。
サーバとクライアントを分けておくことで、クライアントがゲームの情報を書き換える(チート)ことを防ぐこともできます。
サーバにログインして直接アクセスしない限りそうしたことはできないからです。
クライアント・クライアント型のシステムを実行するときの最初のハードルは、接続を確立することです。
一般のルーターはデフォルトでは外部からの接続を受け付けない設定になっています。
なので、アプリを使っているどちらの側からも接続を開始できません。
ホールパンチングという方法でこれを回避することもできるのですが、話すと長くなるので FAQ では書かないことにします。
次の課題はどうやってチートを防ぐかです。
それにはゲームの全ステップごとに、接続している全クライアントにゲームの状態を反映させ、パフォーマンスのチェック、そして同期を取るのが通常です。
さて、あなたが作りたいアプリケーションには上記2つのうち、どちらのタイプの仕組みが適しているでしょうか?
それが決まったら次は、どんなデータを送受信するのかについて思いを巡らせましょう。
それについてはオススメできるような一般的な答えは存在しません。
アプリケーションの仕様によって異なることだからです。
よい判断で正しい選択ができることを祈ってます!
まずは TCP と UDP の違いについてのお勉強です。
TCP はコネクションベースです。通信には信頼性があり、端末から端末へ送信したデータが
必ず届くこと・順番通りに届くことが保証されています。
コネクションベースということは、事前にコネクション(接続)を確立しておく必要があるということです。
後はプログラマは内部的な問題を気にすることなく、データを作って送受信する処理に集中することができます。
簡単に言うと、一旦 TCP 接続を確立してしまえば、どんなデータを突っ込んだとしても、相手側に届きます。どんなにネットの環境が悪くても、です。
もしデータが届かないときは、両方の側にエラーが送信されます。アプリケーションはエラーの情報をもとに動作を立て直すことができます。
と、いいことずくめのようですがデメリットもあります。
TCP ではヘッダー情報を載せるために
最低でも 20byte、最大で 60byte のサイズが必要です。
仮に中身が 1byte だけだとしても、送受信するパケットは最低でも 21byte、最大で 61byte になってしまう、ということです
(TCP にせよ UDP にせよ OSI の下位のレイヤーでのオーバーヘッドが発生しますが、ここではそれは無視して話しています)。
そして、TCP は双方向通信です。送信も受信もできます。
わざわざコネクションを2つ用意する必要はありません(敢えてそうしたい場合は別)。
UDP では TCP のような
信頼性はありません。コネクションベースではなく、
何の保証もありません。
つまり運が悪ければ、送信したデータが受信されないこともある、ということです。
送信したときとは違う順番で受信されることもあり得ます。同じデータを重複して受信してしまうこともあります。
しかも、そうした失敗が発生したとしても UDP はエラーメッセージを出しません。
問題の発生を検知して対処することはアプリの開発者の手に委ねられています。
UDP のメリットは
ヘッダーサイズが常に 8byte(TCP の 40%)であることです。小さなパケットを頻繁に送信するようなケースで帯域幅を節約することができます。
パケットのサイズが大きい場合はヘッダーのオーバーヘッドはあまり問題にならなくなり、どちらのプロトコルでも帯域幅の効率は同じぐらいになります。
UDP では「接続」という概念がないので、誰がどんなデータを送受信したのかを監視するのはプログラマの責任です。
というのも、UDP では通常、サーバーは1つの UDPソケットだけで複数のクライアントからのデータを受け付けるからです(クライアントごとにソケットを用意するのでない限り)。
逆に1つの UDPソケットで複数の相手にデータを送信することもできます。データごとに送信先を設定する、という仕様だからです。
「TCP と比べて不便な点がたくさんあるのに、わざわざ UDP を使う物好きは一体誰だ?」
そんなふうに思ってしまうかもしれません。
そうですね……もしも UDP の上に自前で信頼性の高いプロトコルを構築するならば、"オーダーメイドの TCP" として使えるかもしれません。
アプリケーションのために必要なことだけをして、余計なことはしない。
通信のオーバーヘッドを節約しつつ、処理が速いという UDP のメリットを享受してレイテンシ(遅延時間)を少なくすることができる。
なので、レイテンシを重視するようなアプリケーションでは TCP ではなく UDP が使われています。
ですが、ネットワークアプリケーションの開発経験が少ないうちは大人しく TCP を使っておくのが無難です。
帯域幅やレイテンシといったことはアプリを商用化でもしない限り問題になりません。
商用化を考えるようになる頃には TCP と UDP のどちらを使えばいいかなんて簡単に決断できるぐらいの経験を積んでいるはずです。
ブロッキングソケット と ノンブロッキングソケット、どっちがいい? セレクターの仕組みも教えて。
開発するアプリケーションの種類、または好みによります。
もしネットワークプログラミングの勉強を始めたばかりで、
初めての echo サーバ(データを待ち受けて、受信後すぐにレスポンスを返すサーバ)を書くということなら、ブロッキングソケットを使っても問題ありません。
この場合、サーバはやってきたデータへ返信するだけですので、好きなだけブロックしていられます。
しかしサーバ側で他の処理もしなければいけない場合、例えば内部の状態を毎フレーム更新する、といった役割がある場合は、
更新スレッドがブロックされるような事態は絶対に避けねばなりません。
つまり、スレッドを分離してブロックするか、you call blocking operations when you know they should not block using selectors (※訳注:ごめんなさい、訳せませんでした)か、
または素直にノンブロッキングソケットを使っておくことになります。
ブロッキングソケット1つ1つを別々のスレッドにするとスレッド数が多くなりすぎるのでオススメできません。
スレッドの数が増えすぎないことがわかっている場合限定です。
最初はノンブロッキングソケットの方が簡単そうに見えるかもしれませんが、
ノンブロッキングの場合、データを送受信する前にソケットが使えるかどうかを確認しなければならず、毎回たくさんのシステムコールを実行しなければいけません。
単にソケットが読み込み可能かどうかを確認するだけでも多大なオーバーヘッドが発生してしまいます。
ソケットの数が少ないケースであってもコストの大きな処理です。
そのためにセレクターというものがあります。
上記の問題を解決するために、たくさんあるリソースのそれぞれが利用可能かどうかを同時に、または効率的な方法で調べる機能が OS に備わっています。
どういう原理か? まず、どのリソースをモニターしたいのかを OS に通知します。すると OS は指定されたリソースが利用可能であれば、
セレクタオブジェクトの特定のフィールドに値をセットします。
アプリケーションの側では該当のフィールドに値がセットされているかどうかを確認するだけです。
OS の側でも実際に何かが起きたときだけフィールドをセットすればいい。リソースが利用可能かどうかを調べる方法として非常に効率的です。
SFML の sf::SocketSelector がこの機能を全てラッピングしています。
ソケットが利用可能かどうかをこのセレクタに訊ねることができます。あとの細かい操作は内部で処理しておいてくれます。
一番無難なのは、セレクターとブロッキングソケットを使うことです。どんなケースにでもあまり問題なく対応できます。
もっと効率的な新技術がどんどん出てきていますが、今でもセレクターはいろいろなアプリケーションに使われています。
これは最も解決困難な「問題」の1つですね。
エラーの元になる要因が山のようにあります(プログラマの責任じゃないケースも多い)。
一般的な解決策というものはないので、チェックするべき事項をリストアップしておきます:
- 単なるプログラミングのミスではないかどうか? ドキュメントをよく読んで、アプリケーションの目的が実現されるようなコーディングになっているかどうかを確認してください。
- 接続先のアドレスは正確かどうか? 宛先を指定する方法は3つあります。
- ローカルアドレスで指定(例:192.168.1.1)(192.168..、10...*、172.16.. ~ 172.31.. はどれもプライベートネットワークです)
- グローバルアドレスで指定(例:123.123.123)
- FQSNで指定(例:www.sfml-dev.org)(www がホスト名、sfml-dev.org がドメイン名)
- データのやりとりを妨害するようなものは接続環境の中に存在していない?(ルータの設定、ファイアウォール、等々)
ありがちなのはポートが閉じられているか、NAT のポートフォワーディングの設定ができていないケースです。
-
データは本当に送信されているか? 宛先のアプリケーションに届いているか?
送信元のアプリケーションの内部では送信処理が成功しているなら SFML はエラーを出しません。しかし OS がデータを送信するのを止めていることがあります。
こうした問題が起きているかどうかを調べるには Wireshark のようなパケットキャプチャツールを双方の環境にインストールしておくとよいです。
- データはルータから外へ出ているか? ルータが外へ出て行くデータをブロックしていることがあります。
-
データは宛先のネットワークに届いている? 正しくフォワードされている?
データが送信元のネットワークから出ているのに宛先のネットワークに届いていない場合は、ポートを変えてみましょう。
ISP によっては特定のソフトウェアからのトラフィックをブロックするというポリシーがあったりします。
よりよいフィルタリングの方法を模索しようという気がないのですね。本当にその特定のソフトウェアからのトラフィックだけをブロックするのではなく、
ポートを丸ごとブロックしてしまっている。
運悪くそういうポートを使ってしまっているときは、別のポートに変えてみましょう。
-
使っているポートがブロックされていないとしたら……これは本当にレアなことなのですが、
通信経路上のどこかの ISP のネットワークでエラーが発生しているという可能性もあります。
もし本当にそうなら運の尽きです。日を改めて出直しましょう。または仲間を募ってその ISP に苦情の電話をかけまくりましょう。
-
ISP が何も問題はないと答えたとしても鵜呑みにしてはいけません。彼らが契約上そう答えることになっている場合は別ですが、
電話を終わらせようとしているだけかもしれません。
- 上記のどれも当てはまらないときは、SFML のフォーラムにアクセスして助けを呼びましょう。
残念ながら SFML 自体にはそういう機能はありません。
アプリケーションの見た目のスタイルやデザインは OS や実行環境によって違うものです。
そういうわけで SFML としては、アプリケーションの見た目のスタイルやデザインをコントロールするような機能を提供できないのです。
その代わり、sf::Window::getSystemHandle() 関数でウィンドウのハンドルを取得できます。
このハンドルを使って、アプリケーションを実行している OS や実行環境でウィンドウのスタイルを操作することができるかもしれません(がんばって!)。
以前あった getFrameTime() は どうなっちゃったの?
getFrameTime() は 2012年初頭に SFML から削除されました。
理由はこちらをどうぞ:
http://en.sfml-dev.org/forums/index.php?topic=6831.0
代わりに sf::Clock オブジェクトを作って自前で時間を計測してください。
デメリットよりメリットの方がたくさんあります:
- 正確に時間を計測できる( getFrameTime() で得られるのは、前回のフレームの間に経過した時間)
- コード内の任意の二点間の経過時間を計測できる
- 細かい設定が可能
setFramerateLimit() で指定した通りのフレームレートになってくれない
setFramerateLimit() は内部で毎フレーム sf::Sleep() をコールしています。
sf::Sleep() の内部的な都合にはついては
こちら をご覧ください。
SFML では UTF-16エンコーディングでの国際標準の文字セットによる文字の入力と表示をサポートしています。
sf::Event::TextEntered で 入力イベントを受け取って sf::String 型の文字列でデータを得ることができます。それを sf::Text で画面に表示できます。
sf::String から別の型に変換するには? その逆も。
sf:String に変換するということであれば、お手元のオブジェクトをそのまま sf:String のコンストラクタに入れてみてください。
sf::String sfml_string( cpp_string );
sf::String には 標準 C++ の文字列型からの暗黙的な型変換をしてくれるコンストラクタがたくさんあります。
どんな感じなのか見たいときは
sf::String のドキュメントをご覧下さいませ。
C++標準ではない文字列型から sf::String に変換したい場合は、まずは C++標準の文字列に変換するとよいです。
独自の文字列型を持っているライブラリではその文字列型から C++標準の文字列型への変換をサポートしているはずです。そのはずです!
sf::String から何らかの独自の文字列型に変換するときにも、やはりまずは C++標準の文字列型に変換して、それから目的の文字列型に変換するとよいです。
sf::String は std::string や std::wstring への暗黙的な型変換をサポートしています。
例えば:
std::cout << sfml_string << std::endl;
cpp_string += sfml_string;
std::size_t pos = cpp_string.find( sfml_string );
↑のような書き方は全て OK です。
暗黙的な変換に丸投げしてしまうのは気持ち悪いというアナタは明示的な変換関数を使うとよいです。
.toAnsiString() や .toWideString() をどうぞ。
内部的には sf::String はデータを std::basic_string<sf::Uint32> で保持しています。
なのでこの型(C++標準の型です)へ変換するときにはデータのロスはあり得ません。
ところが この型に直接変換する機能は sf::String ではサポートされてません。
イテレータを使ってください。
std::basic_string basic_uint32_string( sfml_string.begin(), sfml_string.end() );
一旦 std::basic_string<sf::Uint32> を取得してしまえば std::string の全機能を満喫できます。
なにしろ std::string は単に std::basic_string<char> の typedef(別名) ですから。
スレッドは上級者向けの機能です。
スレッドを使うとパフォーマンスが向上するというウワサに惑わされて手を出してはいけません。
下手をするとパフォーマンスが低下てしまうこともあります!
スレッドを使いたくでも、本当に使うべきかどうかは、コードを書き始める前によーく考えましょう。
仮に、スレッドを使うと本当にパフォーマンスが上がるのだとして、どういう仕組みでそうなるのかをハッキリと理解できないとしたら、スレッドを使うのは諦めた方がよいです。
さて、これから開発するアプリケーションでスレッドを使うとイイコトがある! と自信を持って言える場合、
次はメモリアクセスの仕組みに注意を払いましょう。
- 別々のスレッドで同じメモリを同時に読み込んだり、読み込み中に書き込みも発生することはない?
- 別々のスレッドで同じメモリに同時に書き込みが発生することはない?
読み込みだけなら別々のスレッドで同時に行っても基本的に問題ありませんが、上記のようなケースを回避するためにミューテックスを使いましょう。
SFML には クロスプラットフォームなミューテックスの機能があります。使い方は
次の項目をどうぞ。
同じメモリへの同時アクセスへの対応がバッチリだとしても、処理がどういう順番で実行されるかは常に疑ってかからないといけません。
スレッドの世界では実行される順番は一切保証されないのです。
異なるスレッド間で処理が正しい順番で行われるかどうかはプログラマであるアナタの腕にかかってます。
良いシステムのデザインとしては、スレッドの使用をオプションとしておくことです。スイッチをオフにもできるようにしておく。
そうしておくとデバッグなどのときに便利です。
ミューテックス(sf::Mutex)の使い方を教えて
sf::Mutex はリソースへの排他的なアクセスのためのロックを取得するためのものです。
排他的なアクセスが不要になればリソースをロックを解放します。
別のスレッドですでにロックされているミューテックスのロックを取得するには、その別のスレッドがロックを解放するのを待つしかありません。
実践的には sf::Mutex を直接ロックしたり解放したりするのではなく、
そのための RAII クラスである sf::Lock を使う方がよいです。デストラクタの中で自動的にミューテックスのロックを解放してくれます。
sf::Mutex や sf::Lock について詳しくは
チュートリアルをご覧ください。
sf::Thread を STL のコンテナに入れられないのはなぜ?
sf::Thread は sf::NonCopyable クラスを継承しています。
どういうことかと言うと、sf::Thread をコピーしたりアサインしたりはできない、ということです。
ですが、これは STL のコンテナの側からの要求でもあります。
ではスレッドプールを実装したい場合、どうやって複数のスレッドを STL コンテナに入れたらいいのでしょう?
答えはシンプルです。sf::Thread のインスタンスを入れるのではなく、ポインタを入れましょう。
sf::NonCopyable が子クラスに課している制限は あくまでも sf::Thread のインスタンスに適用されます。
ポインタをコピーする分にはコピーコンストラクタやアサインメント演算子は起動されません。
なのでポインタのコピーを作ってアプリ内でたらい回しにしても sf::NonCopyable の制限には抵触しません。
ただ、生のポインタを取り扱うのは C++ としては時代遅れだったりもするので、
上記の技を使うときには
スマートポインタを使うといい感じです。
sf::sleep の実際のスリープ時間が指定した通りにならない
sf::sleep() をコールすると、内部で OS にあれこれとリクエストすることになります。
その時点でのスレッドを停止して、得られた時間をタスクスケジューラを通して、実行時間を必要としている別のタスクに割り当てる。
対象はプロセスだったりスレッドだったり、サポートされていればファイバーでも同じです。
マルチタスクの環境では CPU は本当にスリープしてしまうわけではありません。
スリープの機能を実現するには OS ごとのルックアップテーブルへのエントリが必要です。
処理時間を有効活用するため、次のタスクがあるときにはルックアップテーブルがスケジューラに、スリープしているスレッドの処理をスキップするように伝えます。
OS ごとのスリープの仕組みによって、スリープ時間の計測のされ方、および、スリープを解除するタイミングのパフォーマンスが異なります。
sf::sleep() が予定よりも早く解除されたり、予定よりも長引いたりする理由はいろいろ考えられます。
OS が内部で何をしようとしているか、または運次第です。
上に書いたように、スリープしている時間を計測してスリープを解除するのは OS の役割です。
解像度の高いタイマーが全てのシステムで利用可能というわけではないので、デフォルトの解像度は低めに設定されています。
たとえばシステムタイマーの解像度が 10ms だとして、11ms のスリープ時間を指定したとします。
すると OS は大抵その数字を繰り上げて、スレッドを 20ms スリープさせることになります。なぜ 20ms にするかと言うと、解像度の数字の倍数だからです。
こうした場合、sf::sleep は指定したよりも長くスリープすることになります。
一方、5ms のスリープ時間を指定したとします。しかも指定したタイミングは OS内部のシステムタイマーが切り替わる直前だったとします。
すると "10ms 経過した" と OS にカウントされ、実際に 5ms 経過する前にスリープが解除されることになります。
こうした場合、sf::sleep() のスリープ時間は指定したよりも短くなります。
最近のバージョンの SFML では sf::sleep() のスリープ時間をできるだけ指定通りにするために、sf::sleep() がコールされている間、タイマーの解像度を一時的に上げています。
一つ覚えておいて欲しいのですが、
仮に正確に OS がスリープ時間を計測して、時間経過後にスレッドのスリープを解除したとしても、
スレッドの実行がすぐに再開されるとは限りません。
スケジューラが次に実行するタスクを選択するタイミングを逃すことがあるのです。
すると次のタイミングを待たなければならなくなります。
こうした場合、スリープしている時間そのものは指定した通り正確なのだけれども、見た目のパフォーマンスとしてはスリープが長引いているように見えてしまいます。
SFML では 0ms のスリープ時間を指定することはできないのですが、仮に 0ms を指定したとしたら、
ほんの少しだけ時間がかかっていることに気付くはずです。
通常、OS に 0時間を指定したとしても別のスレッドに処理時間を割り当てるために時間がかかってしまうからです。
結局のところ、sf::sleep() は あくまでも目安であって "約束" ではないということです。
スリープ時間が長ければ長いほど、正確さが増します。
スリープ時間が短ければ短いほど、誤差が大きくなり、運任せになります。
RAII は 「Resource Acquisition Is Initialization(リソースの確保は初期化時に)」 の略です。
プログラミングのイディオム、つまり有名なテクニックで、C++ だけでなく他の言語に対しても使われています。
元ネタは C++ での例外処理のやり方です。
コードの中のあるブロックで例外が発行されたとき、処理をジャンプさせてアプリケーションの流れを止めずに実行し続ける。
もし、こうした処理の中に、使用中のリソースを解放するコードが含まれていたらどうでしょうか?
リソースを解放するコードが必ず実行されるとは限らない、ということになってします。
この問題に対処するために RAII では、全てのコードが実行されるとは限らなくても、オブジェクトを解放するコードだけは確実に実行されるようにします。
該当するスコープの外へ処理が移るとき、オブジェクトは破棄されるべきだからです。
内部でオブジェクトを持っていたり、プログラムをクリーンな状態に保ちながら実行を続ける必要があるようなリソースであれば、こうした技法が有効です。
たとえば sf::Texture が いい例です。
どんなことがあっても、スコープの外へ出て sf::Texture が不要になったときには 内部で使っている OpenGL のリソースは解放されます。
今挙げた例と同じことが、動的に確保したメモリについても言えます。
動的に確保したメモリも、用が済んだら解放する必要があるリソースです。
このため、近年の C++ では RAII が行われるように推奨すべく、スマートポインタの仕組みが言語仕様の中に取り込まれるようになってきました。
それは拡張機能だったり、C++11 では STL の一部だったりします。
そうした機能で管理されたメモリであれば RAII の考え方の通り、スコープの外に出たときに(所有権共有ではないもの。scoped_ptr など)解放されることが保証されます。
メモリ管理のことをあまり心配しなくてもよくなるので、動的に割り当てられるオブジェクトの取り扱いが簡単になります。
こちらの記事 にもっと詳しいお話が例を交えて載っています。
自動的なメモリ管理の機能を無理矢理使わないといけないわけではないですが、
実際のところ、開発中のプロジェクトが大きく複雑になるにつれて、メモリ管理のようなことをするのは難しくなります。
一般的に言って、メモリ管理をそうした自動的な機能に任せることで、アプリケーションのもっと本質的な箇所に集中して開発できるようになります。
それだけではなくデバッグも容易になり、メモリリークをほぼ根絶することもできます。
C++ は長い歴史のある言語です。最新のバージョンである C++11 では新たなメモリ管理の仕組みがたくさん STL に組み込まれています。
おかげで、拡張機能を用意したり自前のライブラリを作ったりしなくても、そうした機能を使うことができます。
スマートポインタというのはですね、その名の通りですね、えーっと……スマートなのです(ニヤリ)。
通常の "生ポインタ" は、それ自体は単なる数値です。オブジェクトが位置しているメモリ内のアドレスを表しているだけです。
その値を通してプログラマが何か操作をしない限り、オブジェクトには何も起きません。
対応するメモリブロックを解放するか、アプリケーションを閉じて、割り当てられたメモリページが破棄されるまでオブジェクトはそこに居座り続けます。
一方、スマートポインタはプログラマが操作をしなくても自分で行動します。
生のポインタと違って、単なる数値ではなく、ポインタが指しているオブジェクトを管理します。
プログラマは特定のメモリブロックをいくつのポインタが参照しているかを把握できるようになります(shared_ptr)。
または、複数のポインタが同時に特定のメモリブロックを参照するのを防ぐこともできます(unique_ptr)。
そして何と言っても、「オブジェクトが不要になった」とスマートポインタが判断したとき、プログラマの代わりにメモリを解放してくれます。
グローバル変数を使うのはお行儀の悪いコーディングと言われています。
開発し始めの段階では使いやすくて便利に思えるかもしれませんが、
プログラムが大きくなってくると頭痛の種になってきます。グローバルスコープのどこで何を宣言したのかがわからなくなってきたりします。
プリミティブ型ではないオブジェクトをグローバルスコープで宣言したときの最大のデメリットは、
いつインスタンスが作られて、いつ破棄されるのかを(開発者であるアナタが)把握できなくなることです。
特に、インスタンス生成されるときに事前に何らかのリソースが取得可能な状態になっていなければならないようなオブジェクトがグローバルな場所に宣言されていて、
main() 関数の実行前の位置にコードが書かれていると、話がややこしくなってしまいます。
同じように、main() 関数が終了した後に、そのオブジェクトが破棄されるのかもしれません。
すると、そのオブジェクトが内部で保持しているリソースの解放処理は自前のクリーンアップ管理の仕組みに委ねられることになってしまいます。
最悪、main() 関数が終了するときにはすでにリソースマネージャー自体が破棄されてしまっているかもしれません。
そうなるとメモリリークが発生します。お行儀が悪い。
さらに言えば、初期化および解放処理の順番がハッキリしません。
ソースの中でどういう順番で宣言されているかによりますが、結局のところコンパイラによって内部仕様が異なっており、要するに運任せになってしまいます。
グローバル変数のもう一つの問題は、遅かれ早かれネームスペースを圧迫していく、ということです。
ネームスペースを分けて宣言しない限り、単一の巨大なグローバルなネームスペースに宣言されることになります。
するとどうなるか?
とある関数の内部で宣言したローカルな変数の名前が、たまたま、グローバル変数の名前と重なってしまうかもしれない。
そうなると、気付かないうちに、そのグローバル変数が新たに宣言したローカル変数の影に隠れてしまいます(コンパイラがそういうケースを検知して警告を出してくれることもある)。
とある人々は「ハンガリアン記法を使えばこの問題を解決できる!」とご提案されているのですが、
近年のプログラミング業界の傾向としては、グローバル変数の使用と同じぐらいハンガリアン記法も避けられています。
さらにさらに、グローバル変数を使うとコードのモジュール性も低下してしまいます。
グローバル変数にはどこからでもアクセス可能です。なので、いくらモジュールのインターフェイスがしっかりと定義されてアクセスが上手に制御されていても無駄になってしまいます。
そうしたモジュールを使っていると、目に見えないところで依存性が高まっていきます。
メンテナンスが難しくなるだけでなく、追跡するのが非常に難しいバグの温床になります。
変数がグローバルであるということは、その変数へのアクセスを制限できないということです。いつ、どこから値を変更されるかわかりません。
これだけ悪さをしてもまだ満足しないらしく、グローバル変数はマルチスレッドの環境でもイケない遊びをしやがります。
別々のスレッドからのグローバル変数へのアクセスはミューテックスでプロテクトされる必要があります。
そのために開発者は余計な気を遣わなければならないし、下手なプロテクトのせいで同期処理のための無駄なオーバーヘッドが発生してしまいます。
かと言ってグローバス変数をプロテクトせずにマルチスレッドを使っていると、密やかにバグが忍び寄ってきます。
メモリ管理を上手にできればパフォーマンスを悪化させずに済むのですが、
だからと言って、わざわざグローバル変数を使う理由はどこにもありません。
ちなみに、同じことがスタティック変数にも言えます。
違いは単に可視性(クラスや関数のスコープ)と、関数内のスタティック変数の場合はコンストラクションのタイミングです(プログラムの開始時ではなく、最初の呼び出し時)。
関数内のローカル変数のコンストラクションの処理時間を "最適化" する目的で static を使おうなどと思わないこと!
変数は、それが使われるスコープの内部に閉じ込められるように心がけましょう。
処理がスコープの外へ出れば変数は破棄される。ライフタイムの管理です。同じように、インスタンス生成と保持をするのは、仕様上そのオブジェクトを所持する必要のあるオブジェクトの内部だけにとどめておきましょう。
他のオブジェクトや関数へ渡すときには参照かポインタを使いましょう。
値で渡すのは避けること。
オブジェクトをコピーできなくて、従って値渡しができないこともあるでしょう。
そうでなくても、コピーするだけで一時メモリが割り当てられてしまうので処理に時間がかかってしまいます。
もし C++11準拠のコンパイラをお使いでしたら、プログラム内で使っている標準ライブラリのオブジェクトの多くに所有権移動コンストラクタが定義されていることをご存知のことでしょう。
こうしたコンストラクタのおかげで値渡しのダメージが軽減されます。
条件が合えば、コンパイラは Rvalue参照版の関数を使って、結構な度合いで処理時間を短縮してくれるのです。
要はシングルトンのクラスってグローバル変数なのですよ。甘いマスクに騙されるな。
グローバル変数と同じなので、抱えている問題点も同じです(コンストラクション/デストラクションのタイミング、目に見えない依存性、マルチスレッドでの問題)。
オブジェクト指向のデザインパターンの1つとして有名なので、「彼ってオブジェクト指向だし、いい人に決まってるわ」と思ってしまうかもしれません。
そうした判断が一般的に疑わしいかどうかはともかく、このケースに関しては明確に問題であると申し上げます。
クラスをグローバルにして持ち回るのはオブジェクト指向ではありません。
それどころか、シングルトンはモジュール性やカプセル化といったオブジェクト指向の中心的な原則を破ってしまいます。
よくある誤解なのですが、一回しかインスタンス生成されないオブジェクトはシングルトンである、というのは間違いです。
シングルトンの目的は、特定のクラスのインスタンスが2つ以上存在しないように仕様上の制限をかけることです。
それはそれで役立ちそうなアイディアに聞こえるかもしれないのですが、
シングルトンの技法は副作用を抱えています。
その唯一のインスタンスに、グローバルなアクセスポイントを与えてしまっているのです。
そのせいで、本来の目的としているメリットよりもデメリットの方が多かったりするのです。
もちろん、ただ一つのインスタンスだけが存在するべきクラスが必要なケースもあります。
例えばレンダリングのようなマネージャー的なタスク、リソースのハンドリング、コンフィグの設定および管理などです。
しかしながら話は実に単純で、インスタンスを1つしか持ちたくないなら、インスタンス生成を一回だけにすればいいのです。
ついうっかり2つインスタンスを生成してしまうかもしれない、などというのは大げさな話です。
そういったオブジェクトのインスタンス生成をするための広くて見晴らしのいいスペースはソースコード内に必ずあるはずです。
仮にうっかり2つ生成してしまった場合に大きな問題が発生するのだとしても、アサーションを使えば簡単に回避できます。
グローバル変数を使うリスクに比べれば取るに足らない手間と言えるでしょう。
チュートリアルの「開発環境を整えよう」はよく読んだかな?
以下の項目をチェックだ:
- コンパイラに SFML のヘッダーファイル群の場所は伝えた?
- IDE に SFML のライブラリの場所は伝えた?
- 使いたいモジュールのヘッダーをインクルードした?("SFML/[モジュール名を大文字で].hpp")
- 使いたいモジュールのライブラリをリンクした?(本ドキュメントの「依存性」の項目を見よ)
- Windows の場合、libsndfile-1.dll and openal32.dll 実行ファイルのフォルダにコピーした?(SFML の SDK に入ってます)
モジュールごとの DLL(と、依存しているものも)も入れた?
- Linux の場合、必要なライブラリをインストールした?(SFML のフォルダで sudo make install せよ)
上記が全て問題ないのに、SFML が動こうとしない? では 「
バグ発見!」の項目を見るべし。
IDE のエラーメッセージをもっと詳しくするには?
コンパイルやリンクってエラーになることがありますよね。
プロジェクトの設定をよーく見直して、さらにチュートリアルの内容とよーく見比べても原因がわからなかったりもする。
IDE(統合開発環境)というのは背後で動いているたくさんのツールのフロントエンドに過ぎません。
Visual Studio にしても Eclipse にしても Code::Blocks にしても、していることは同じで、そうした背後のツールを使った作業を自動化して、
プロジェクトの開発作業をやりやすくしています。開発作業を一つの環境(ソフトウェア)内で出来るようにしているので "統合開発環境" というわけですね。
IDE がないとどうなるでしょう?
テキストエディターでプロジェクトのソースファイル(たくさんあるでしょう)を直接書いて、コマンドラインを通してコンパイラやリンカに手作業で指示を出さないといけません。
IDE のいいところはコンパイラやリンカからの出力情報を、わかりやすい形式で表示してくれるところです。
たとえばエラーの表示をクリックすると、該当の箇所を表示してくれたりします。
IDE が背後でしていることは何かと言うと、「ビルド」のボタンを押すと、コマンドラインを自動的に発行してくれます。
もちろんコマンドラインは自分で手書きすることもできるのですけど、ハッキリ言って面倒くさい作業です。
そして、出力されたメッセージを受け取っています。メッセージの内容は、発行したコマンドに対するワーニングやエラーです。
デフォルトでは、ほとんどの IDE は背後で発行されているメッセージを表示しない設定になってます。
ですが、まさにそういうメッセージこそ、エラーを解決するための役に立つ情報です。
ありがたいことに IDE にはそうしたメッセージの表示/非表示を切り替えるオプションがついてます。
実際に IDE が背後でどんなコマンドを発行するかはプロジェクトの設定によります。
設定は IDE のユーザーインターフェイスで変更できます。
正しく設定しているつもりでも、実際に発行されているコマンドを見てみないことにはわかりません。
コマンドラインはたくさんのフラグやパラメータの集まりです。
意味を理解するにはそのコンパイラやリンカのドキュメントを見てください。
フォーラムでビルドに関する問題について質問するときには、ビルドログ(コンパイラやリンカへ発行されたコマンドや生の出力情報)を書き添えるようにしましょう。
ビルドログの中には必要な情報が詰まっているので、下手に IDE のスクリーンショットを貼り付けたりするよりもずっと効率的で確実な情報提供の方法です。
経験豊富なユーザーは貼り付けられたビルドログの中からすぐにミスを発見できます。すぐに質問が返ってきても驚かないように!
◆ Code::Blocks の場合(全バージョン・全OS共通)
まず、コンパイラの設定ウィンドウを開きましょう。
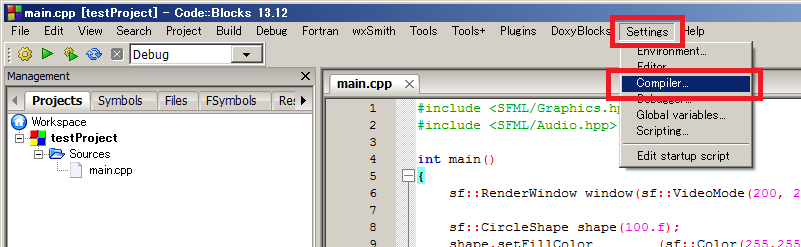
"Other Settings" タブを開いて、"Compiler logging:" の欄で "Full command line" にします。
ビルド終了後、タブを "Build log" に切り替えます。
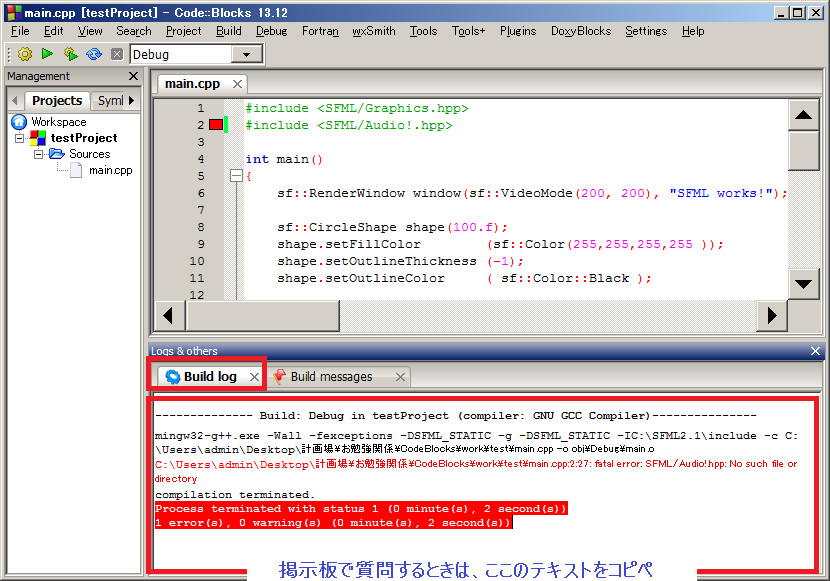
ビルドログをよく読んで、問題解決に役立つ情報がないか探しましょう。
それでも自力で解決できないときはフォーラムで質問です。
そのときには、ビルドログの出力テキストをコピペしましょう。
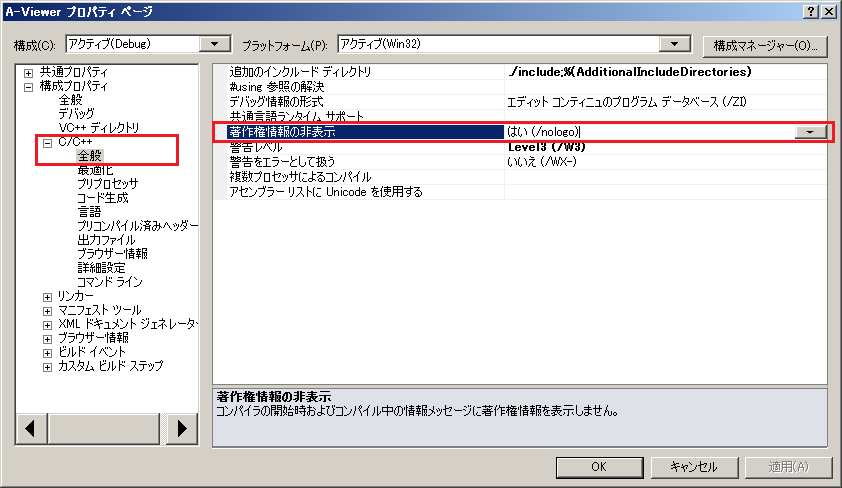
◆ Visual Studio の場合(2008/2010/2012/2013 ・ OS:Windows)
まず、プロジェクトのプロパティ設定画面を開きましょう。
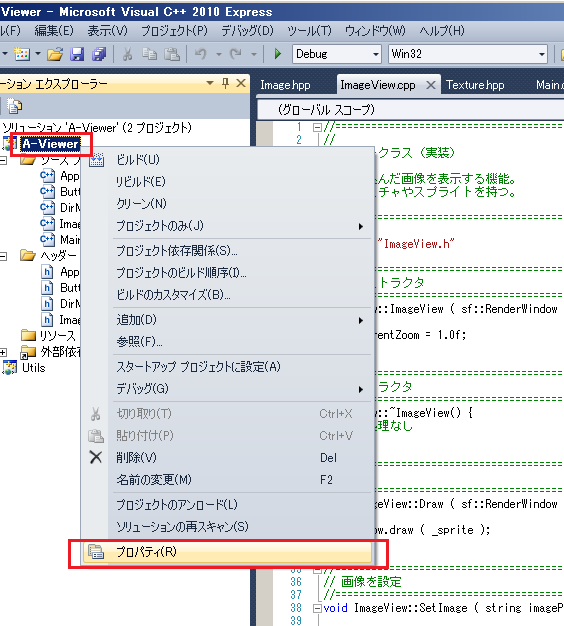
ビルドしようとしているプロジェクトのプロパティ画面かどうかをよく確認しつつ。
C/C++ → 全般、そして 「著作権情報の非表示」を「はい(/nologo-)」に。
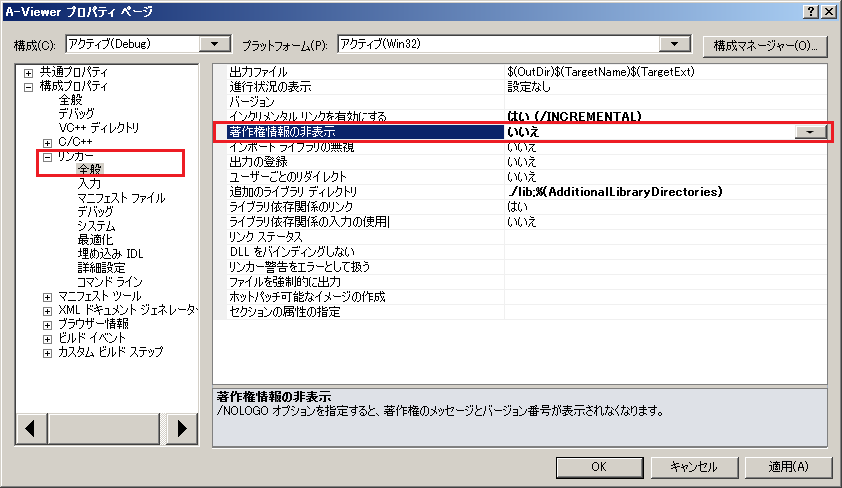
Linker → 全般、そして、「著作権情報の非表示」を「いいえ」に。
プロジェクトをビルド。
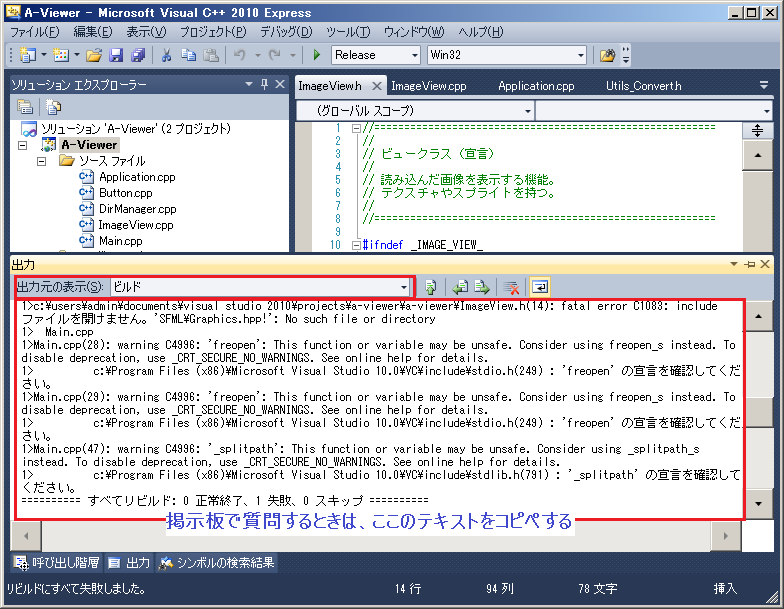
ビルドログをよく読んで、問題解決に役立つ情報がないか探しましょう。
それでもわからなければ掲示板で質問を。
その際には、出力されたテキストをコピペしましょう。
◆ ちなみに
掲示板で質問するときにはログを <code>~</code> タグで囲んでおくと読みやすくなります。
強制改行を防げるだけでなく、等幅フォントで表示されるので、複数行にまたがるときの読みやすさが向上します。
◆ 訳注 ◆
ここで言っている掲示板というのは SFML の公式サイトにあるフォーラムのことを指しているのだと思います。
私自身は実を言うとそのフォーラムに書き込みをしたことがないのでわからないのですが、
おそらく、そのフォーラムでは <code> タグが使えるようになっているのでしょう。
「<code> タグを使いましょう」というのはそのフォーラムに特有の話であって、一般論ではないと思います。
が、「ログをコピペしましょう」というのは、公式のフォーラムに限らず、掲示板で質問するときの心がけとして一般的に言えることだと思います。
「未解決の外部シンボル △△△ が関数 ○○○ で参照されました」のエラーが出まくる!
リンクの仕方についての項目を読んでください。
それでもダメなら
IDE のエラーメッセージをもっと詳しくする方法を試してみてください。
それでもまだダメなら、フォーラムでお気軽にご質問ください。
SFML では 64bitのアプリケーションを作れないの?
まず自問してみましょう。「私は本当に SFML で 64bitアプリを作る必要がある?」
64bitアプリにはメリットもありますが、コンパイルやリンクの仕組みをよく理解するまでは、初心者にはオススメできません。
ややこしいのは Windows の仕様のせいでもあります。
最近のバージョンのものは 64bitのプロセッサを活用できるようになっていますが、
32bit のアプリケーションも同じように動かすことができるようになっています。
デフォルトでは、ほとんどのコンパイラは 32bit の実行ファイルを出力するようになっています。
64bit の OS 上でアプリを開発しているからと言って、自動的に 64bit の実行ファイルが出来上がるわけではないのです。
よくわからないときには、自分でアプリを作るにしても、ネットで他の人が作ったアプリをダウンロードするにしても、32bit版にしておくのが無難です。
さて、基本的なお話をしましょう。
私たちが毎日使っているプロセッサ(CPU)はマシン語の命令文を実行しています。プログラムとはマシン語の命令文のカタマリです。
プロセッサが理解&実行することができる命令文のセットは "命令セット" と呼ばれています。
その昔、Intel からリリースされたプロセッサが大人気になりました。そのプロセッサたちがサポートしていたのは最初は 16bit のレジスタでしたが、徐々に 32bit になっていきました。
そのプロセッサたちのモデルナンバーの語尾は "86" でした。
そんなわけで、Intel のプロセッサの命令セットは "x86 の命令セット" と呼ばれるようになったのです。
今日では x86 は 32bit の同義語です。
"x86" と書かれている CPU を見れば「あ、32bit なんだな」と、すぐに判断できます。
時が経つにつれ、32bit のレジスタでは段々と不充分になってきました。
メモリアドレスをレジスタの中に記憶する仕組みのせいです。RAM の 4GB までしか使えないのです。
そのため、64bit のレジスタをサポートしなければならなくなってきました。
それが 64bit時代の幕開けです。その頃、最初に 64bit の命令セットを開発したのは AMD でした。
以降 "AMD64" という単語が頻繁に聞かれるようになります。
x64、x86-64、AMD64 はどれも 64bit に対応したプロセッサですが、32bit との互換性もあります。
文法的に正しいソースコードをコンパイルしたとき、コンパイラはそのソースコードを、ターゲットとなる CPU が実行できる命令セットに翻訳します。
コンパイラはいつも、CPU の種類(32bit か、64bit か)に合わせてコードを生成するのですが、
x64 は x86 に対して後方互換性がある(単なるスーパーセットです)ので、x86用にコンパイルされた実行ファイルも実行することができます。
ただし、OS のカーネルがこうした互換性をサポートしている必要があります。
Linux や OS X などのシステムでは互換性よりもパフォーマンスが優先されています。
違う種類の CPU のマシンにバイナリファイルを移動させることはできません。
その代わり、ターゲットにしている CPU の種類に合わせて、より最適化された実行ファイルが生成できます。
自動的に CPU の種類に合わせた実行ファイルが作られる、ということは、つまり、「64bitのアプリになるようにコンパイルしたい!」と、プログラマが自分で言っても意味がないということです。
強引に 32bit システム用にコンパイルして互換性を持たせる方法もないわけではないのですが、この FAQ の範囲を超えてしまうのでここではお話しません。
ともかくそういうわけで、アプリを開発するときに CPU の種類を気にする必要はないということです。
Windows では上でも述べたように、パフォーマンスよりも互換性が優先されています。
マイクロソフトは古いアプリケーションが新しいバージョンの Windows でも動作するようにしなければならず、なかなかサポートを打ち切ることができないのです
(そういうアプリケーションは大抵、オープンソースではない。しかもあまりメンテナンスされない)。
そのため、64bit のネイティブアプリケーションと一緒に 32bit のアプリケーションも動作させられるようにしておかないといけなくなってしまった。
このテクノロジーは "Windows on Windows" や "Windows 32-bit on Windows 64-bit" と呼ばれています。略して "WoW64" です。
どの 64bit の Windows も、32bit版のシステムを内部に持っています。
プログラムが起動されるとき、ローダがその実行ファイルが 64bitアプリか 32bitアプリかをチェックし、対応する DLL を読み込みます。
どちらの CPU用のアプリなのかの情報は実行ファイル自体に埋め込まれているので、外側からはなかなか見分けがつきません。
Windows でアプリを開発する場合、たとえユーザーが全員 64bit版を使っていることがわかっているとしても、32bitアプリとしてソースをビルドするのは、いたってノーマルなことです。問題なしです。
このことが、ライブラリを使ってアプリケーションを開発するときの混乱のもとなのです。
ターゲットにしているのが 32bit なのか 64bit なのかがファイル名にハッキリと書かれてでもいない限り、
そのライブラリが、コンパイラがターゲットにしている CPU の種類と互換性があるものなのかどうか判断できません。
SFML のライブラリのファイル名にはそうした記号がついていません。
なので、どちらの CPU用のライブラリなのかは、ダウンロード(または自分でビルド)したときによく覚えておいてください。
Visual Studio でビルドするときには、リンクされる全てのモジュールについて、それぞれが対象としているマシンの種類(64bit か 32bit か)をリンカがチェックします。
もし、ミスマッチが発見されたらエラーとなります。
その場合のエラーは大体こんな感じです:
fatal error LNK1112: module machine type 'X86' conflicts with target machine type 'x64'
エラーメッセージ内の 'X86' と 'x64' は逆になっていることもあるかもしれません。
このエラーを解決するには、要するに上で述べたようなミスマッチをなくせばいいのです。
たとえば 64bit用のアプリを開発したいのであれば、使うライブラリも全て 64bit のものにする。 32bit用のアプリを開発したい場合も同じです。
GCC や Clang を使ってコンパイルしている場合、上記のようなミスマッチが発生しているかどうかはわかりにくいです。
Visual Studio のような明示的なチェック機能がなく、リンカは単に、ミスマッチしているシンボルを無視します。
すると、まるでリンカがそれらのライブラリを受け付けたかのように見えるのですが、実際には処理が全く行われず「外部シンボルが未解決」のリンカエラーが大量に出ます。
同じエラーは別の原因でも発生する可能性のあるものなので、このエラーが出たからと言って CPUの種類のミスマッチがあったのかどうかは判断できません。
こうしたツールを使っている場合は Windows上で 64bitアプリをビルドするのはオススメできません。
どうしても Windows上で 64bitアプリを開発しなければならない場合は、代わりに Visual Studio を使うとよいです。
◆ 訳注 ◆
ここで何度も出てきた「CPU の種類」というのは、
原文では "architecture(アーキテクチャ)" となっていたのを意訳したものです。
ここでの意味合いに限定して言えば、つまるところ「32bit か、64bitか?」ということだと思われます。
ただ、CPU 関連の用語としては「アーキテクチャ」は、すでにカタカナ語として定着しているような気もします。
お好みに合わせて適宜読み替えていただければと思います。
SFML は決してコンピュータをクラッシュ/フリーズ/ブルースクリーン/ハングアップ させないようにデザインされています。
もしもそうした現象が SFML のプログラムを動かしたときにだけ限定して発生するとしたら、SFML はあくまでも間接的に関係しているだけのはずです。
たとえば、不安定なドライバ(ベータ版だったり、開発ブランチから取得したものだったり)を使っているとしたら、それが問題の根源かもしれません。
それがどうして他のアプリケーションではなく SFML を使ったアプリケーションで不具合を出すのか?
理由は主に、OpenGL と DirectX の世間での地位の差です。
DirectX の方が多くのゲーム等に使われていて影響も大きいので、OpenGL よりもバグが優先的に修正されます。
バグが修正されるのを大人しく待つか、安定版のドライバに変更するしかありません。
不安定なドライバを使っているわけではないとしたら、不具合の原因はオーバークロックかもしれません(自分でチューニングしたか自動的な設定かどうかに関わらず)。
標準のパフォーマンス設定で問題が起きるかどうかを確認してみてください。
デフォルトでオーバークロックされているハードウェアをお使いの場合は、同じ問題を経験した人がいないかどうかネットで探してみてください。
もし他にも同じ問題を経験している人がいるならば、ハードウェアのメーカーに問い合わせましょう。
これはハードウェアの問題なので、自力で出来ることはあまりありません。
ほとんどの場合、想定外の動作は SFML の使い方を間違えている結果です。
大量のバグレポートうち、本当に SFML 自体が原因のものはほとんどありません。
バグを発見したと思っても、それが SFML1.6 であるならば、サポートは大昔に終了していることをここにお伝えしておきます。
どうか 2.4.2 にアップグレードしてください。
SFML1.6 についてのバグレポートは無視されます。そのバグが 2.4.2 にも持ち越されている場合は別ですが、そういうことは滅多にありません。
すでに 2.4.2 を使っているならば、
GitHub にあるマスターリビジョンをビルドしてみてください。
通常のリリース版では不具合があったとしても、開発中の最新版では修正されているかもしれません。
◆ 訳注 ◆
2.5のリリース後でしたが、確認した時点では原文のこの箇所は「2.4.2」のままでした。たぶん深い意味はないと思います。
最新の SFML でもまだバグが発生する場合は、該当の現象だけを再現するような
最小限のサンプルを見せてください。
そうすることで、開発者の方々がエラーの原因を探ることができます。
余っているマシンが手元にあるならば、そちらでも同じ現象が再現できるかどうか試してみてください。
もし別のマシンでは同じ現象が発生しないとしたら、そのマシンの設定と同じになるように、元のマシンの設定を変更してみてください。
怪しい挙動の多くは実行環境やドライバの設定ミスのせいです。
【注意】ベータ版のドライバが原因のバグを報告するのはグッドなアイディアではありません。問題の源は SFML 開発者の責任ではないので、教えてくれても直しようがありません。
もし SFML の内部にバグの原因があって、実行環境とは無関係だという確信がある場合は、
公式サイトに行って、該当のパッケージのフォーラムに報告してください。
その際にはバグに関する詳しい情報を書き添えるのを忘れずに。
使っている SFML のバージョン、システムの設定、バグを再現させられる最小のサンプルコード、それから必要ならばコンパイラやリンカのログ。
そして、同じバグが既に報告されていないかどうかも確認のこと(
検索機能を使うのだ)。
Issue Tracker も確認。あるいは、もしかすると最新のソースでは解決済みなんてこともあるかもしれないので、
closed でも検索。
◆ 訳注 ◆
GitHub のページは SFML公式サイトの "Download → Git repository" から行けます。
または "Development → Repository" です(リンク先は同じ)。
簡単にコンパイルできるソースコードのスニペットです。
つまり:
- 単一のファイルで出来ている(外部の .h、hpp、.cpp ファイルが存在しない)
- コンパイラやリンカのオプションを設定しなくていい
- 必要な動作だけをして、他の動作は一切しない
そうしたサンプルはどうしても必要な場合以外は、長くても 40行を超えてはいけません(必要なヘッダーのインクルード行も含む。もちろん省略してはいけませんよ)。
例えば、こういう感じです:
#include
int main() {
sf::RenderWindow window( sf::VideoMode(640, 480, 32), "Bug" );
/*
バグを再現するコードをこのへんに書く
*/
while( window.isOpen() ) {
sf::Event event;
while( window.pollEvent( event ) ) {
if( event.type == sf::Event::Closed ) {
window.close();
}
}
/*
バグを再現するコードをこのへんに書くこともあるのかも
*/
window.display();
}
return EXIT_SUCCESS;
}
詳しいルールは
こちらに書いてあります。
◆ 訳注 ◆
一般論というよりは、SFML の公式サイトのフォーラムで質問をするときのお約束、という意味合いの話のようです。
最小のコード(minimal code)を作るには?
楽勝ですよ?
- テスト用に別プロジェクトを作って、main()関数だけを書く
- main()関数の中にコードをコピペしてコンパイルが通るようにする
- 問題の挙動に無関係な行を1つ1つ削除しつつ、問題が消えないかどうかをコンパイルして確認
ちなみに、このテクニックは問題を自力で解決するのにも役立ちます。
MinGW などの GCC ベースのコンパイラでは、ライブラリをリンクする順番を気にする必要があります。
たとえば ライブラリA が ライブラリB に依存しているとすると、ライブラリA を ライブラリB の前にリンクするのです。
SFML で言うと、例えば Grapgics モジュールと Audio モジュールを使いたい場合、
リンクの正しい順番はこうです:sfml-audio, sfml-graphics, sfml-window, sfml-system。
動的リンク版の SFML1.6 を使っている場合は、"SFML_DYNAMIC" というマクロをプリプロセッサの設定に追加してあげてください。
静的リンク版の SFML2.3 を使っている場合は、"SFML_STATIC" というマクロをプリプロセッサの設定に追加してあげてください。
SFML2.0以降では、"SFML_DYNAMIC" の定義は無効です。
詳しくは、チュートリアルの Code::Blocks の設定のページをご覧くださいませ。
プロジェクトをビルドできない。でもコンパイラエラーもリンカエラーも出てない。
プロジェクトの設定に対して正しいバージョンのライブラリをリンクしているでしょうか?
デバッグモードでビルドしているならばデバッグ用の SFML を、リリースモードならばリリース用の SFML をリンクです。
メモ。SFML の命名規則:
- sfml-[モジュール名].lib → リリースビルド用(動的リンク)
- sfml-[モジュール名]-d.lib → デバッグビルド用(動的リンク)
- sfml-[モジュール名]-s.lib → リリースビルド用(静的リンク)
- sfml-[モジュール名]-s-d.lib → デバッグビルド用(静的リンク)
動的リンク用のライブラリでビルドしたならば、実行時に実行ファイルと同じフォルダに、対応する DLL をコピーしておいてください。
- sfml-[モジュール名].dll → リリースビルド用
- sfml-[モジュール名]-d.dll → デバッグビルド用
何度やっても "fatal error LNK1112: module machine type 'XYZ' conflicts with target machine type 'ZYX'" が出る。助けて!
"SFML では 64bitのアプリケーションを作れないの?" を見てね。
Windows だと、作ったアプリケーションのウィンドウの後ろに真っ黒なコンソール画面がくっついてきますよね。
プロジェクトを作る段階で "GUIアプリケーション" を選択しておけばコンソールは出なくなります。
IDE の設定で、ビルドするアプリケーションの種類として、
コンソールつきのアプリケーションなのか、コンソールなしの GUI アプリケーションなのかを選択できるようになっているはずです。
が、プロジェクトを作る段階では「空のプロジェクト」を選択し、マニュアル操作でアプリケーションの種類を設定するのがオススメです。
「空のプロジェクト」以外のものを選ぶと自動的にいろいろと設定されて、後々おかしなことになってしまうことがありますからね。
すでに作ってしまったプロジェクトの設定を変更するには:
-
Code::Blocks の場合
プロジェクト名を右クリックして "Properties" を選択。
"Build targets" タブを開く。画面左のリストで "Debug" か "Release" かを選択。
画面右側の "Type" 欄を "Console application" から "GUI application" に変更。
-
Visual Studio の場合
プロジェクト名を右クリックして "プロパティ" を選択。
左端のメニューで "リンカ" → "システム" を選択。
右上の "サブシステム" の欄 を "コンソール (/SUBSYSTEM:CONSOLE)" から "Windows (/SUBSYSTEM:WINDOWS)" に変更。
互換性の高いエントリポイント(main()関数のこと)を残しておくには、
Visual Studio の場合は sfml-main.lib を、Code::Blocks の場合は libsfml-main.a をリンクしておきます。どちらも軽量なライブラリです。
または、GUIアプリケーション用のエントリポイントを定義することでも、コンソールを隠すことができます。
int WINAPI WinMain(HINSTANCE hThisInstance, HINSTANCE hPrevInstance, LPSTR lpszArgument, int nCmdShow)
main()関数を上の関数に置き換えます。通常の main()関数と同じように、実行時に OS から呼び出されるようになります。
何はともあれ、チュートリアルに従っているかどうかを確認。
それから、下記のパッケージがインストールされているかどうかをチェック。
- libx11-dev
- libxcb1-dev
- libx11-xcb-dev
- libxcb-randr0-dev
- libxcb-image0-dev
- libgl1-mesa-dev
- libudev-dev
- libfreetype6-dev
- libjpeg-dev
- libopenal-dev
- libflac-dev
- libvorbis-dev
ライブラリの名前は違っているかもしれません。特にバージョンの数字。
タイトルバーなどのウィンドウのパーツが表示されない
Compiz を使っているなら、オフにしてください。
Compiz は 他の OpenGL アプリケーションと相互干渉してしまうのです。
ウィンドウマネージャーが Metacity ならば、下記のスクリプトで Compiz の オン/オフを切り替えることができます。
#!/bin/bash
pid=`ps --no-heading -C compiz.real | cut -d "?" -f1`;
if [ -n "$pid" ]; then
metacity --replace &
else
compiz --replace &
fi
zlib/ping です。
SFML はオープンソースのプロジェクトにも、プロプライエタリなプロジェクトにも使うことができます。
有料または商用利用のプロジェクトも含まれます。
SFML を使う場合、クレジットか何か一言添えておいてもらえるとありがたいです。強制ではありません。
どうぞ。SFML は商用アプリケーションでの利用可です。
SFML を使っていることをクレジットなどに書く義務もありません。
ただし zlib ライセンスですので、自分が SFML の作者であると自称したり、自前で改造した SFML をオリジナルであると言い張るのはナシです。
はい。SFML は静的リンク可能です。
どの OS でもできます。
ただし、Linux と macOS では特別な理由がない限り動的リンクにしておくことをオススメします。
静的リンクにしたときには、SFML_STATIC マクロを コマンドラインに定義しておくのを忘れずに。
exampleフォルダに入っているコードには個別のライセンス表示がありません。
ということは、本体と同じく zlib/png ライセンスの下にあるということです。
このライセンスに従う限り、好きなように扱って OK です。
zlib/pngライセンスは許容的フリーソフトウェアライセンス(permissive free software license)です。
このライセンスには、このライセンスの下にあるソフトウェアが有料であるという条件は含まれていません。
したがって、SFML は作者に対して使用料を支払う必要がなく、無料で使用することができます。